Classification
- j.reades@ucl.ac.uk
1st October 2025
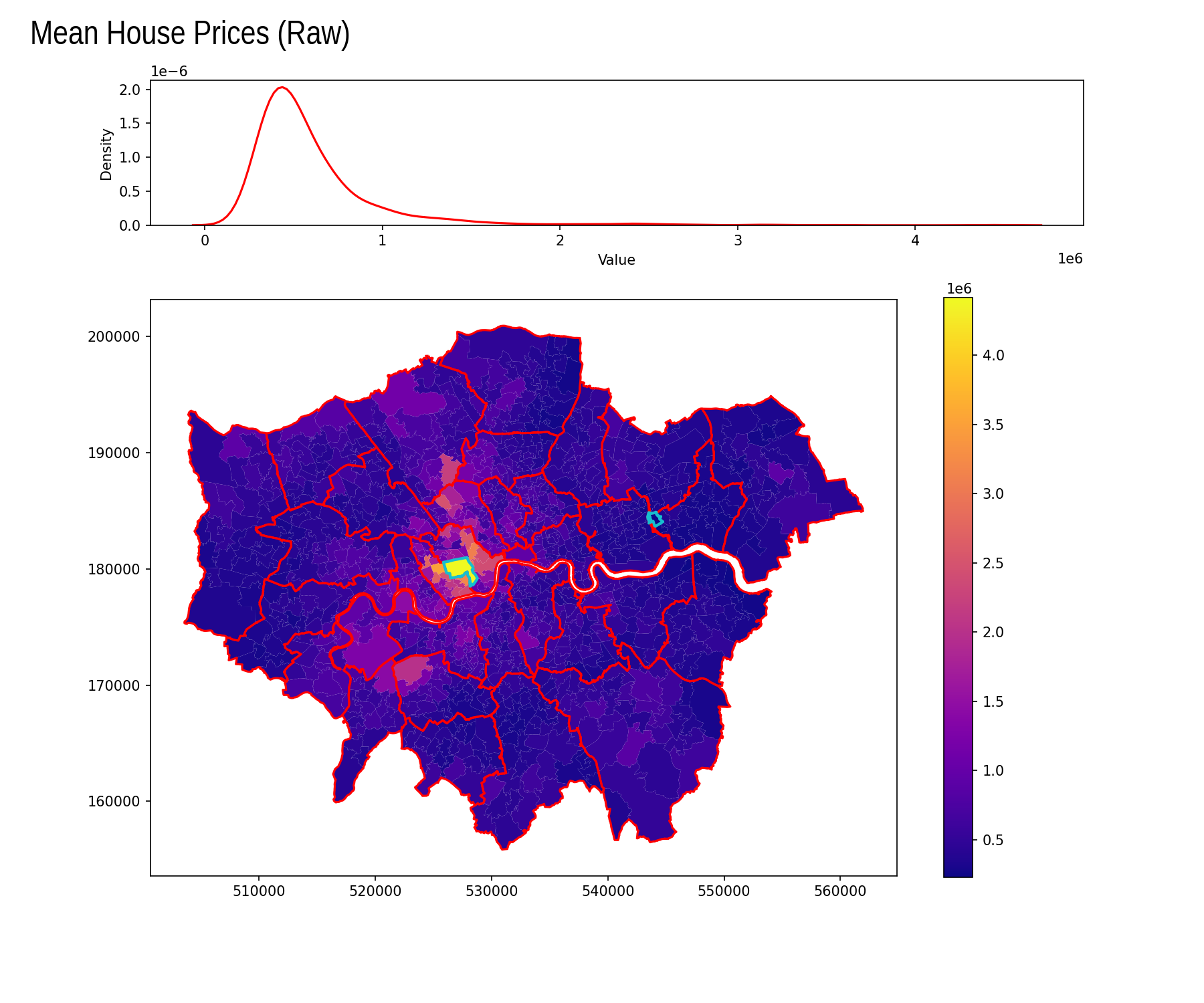
Raw
User Defined
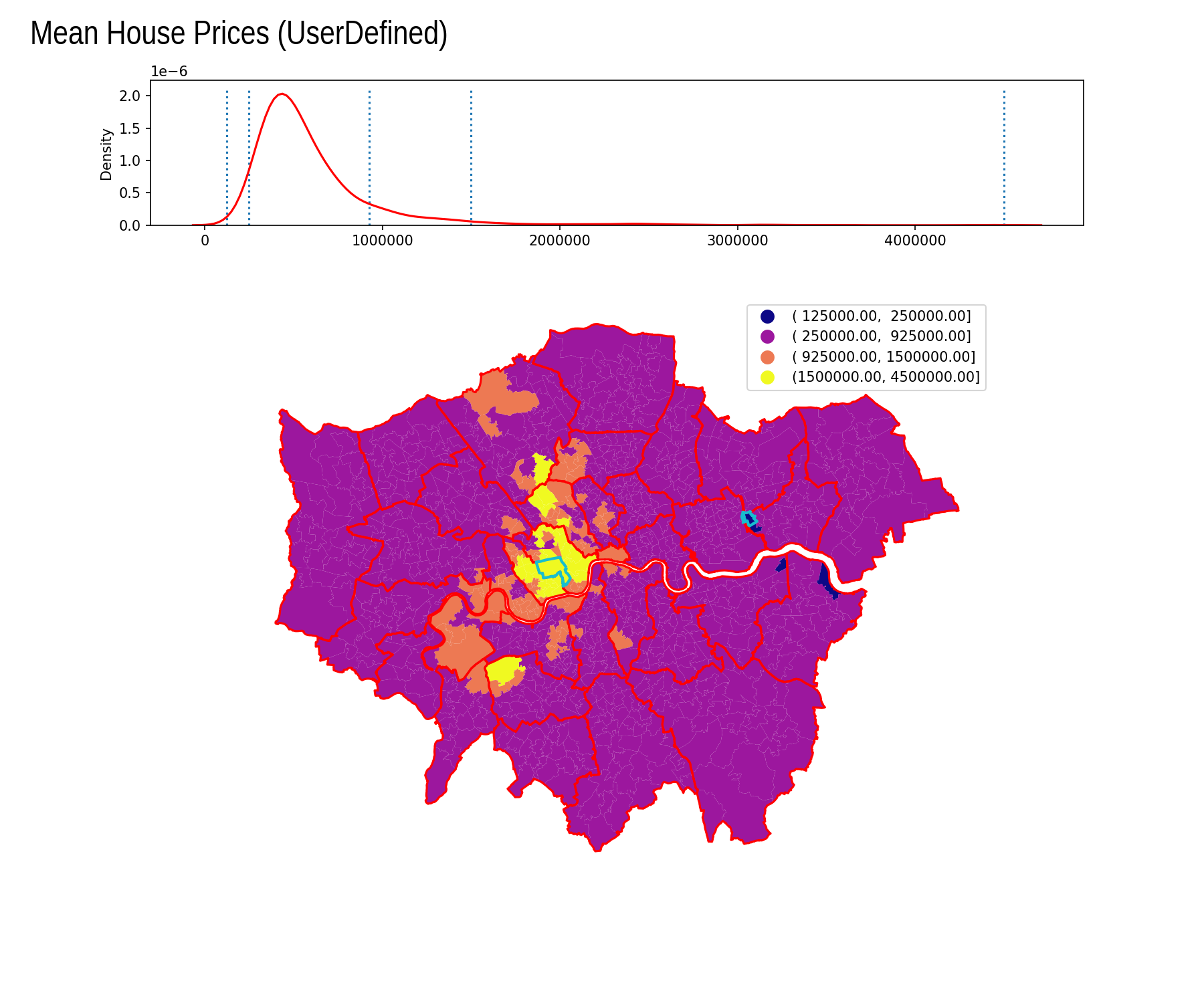
| Interval | Count |
|---|---|
| ( -inf, 125000.00] | 0 |
| ( 125000.00, 250000.00] | 4 |
| ( 250000.00, 925000.00] | 865 |
| ( 925000.00, 1500000.00] | 85 |
| (1500000.00, 4500000.00] | 29 |
Box Plot
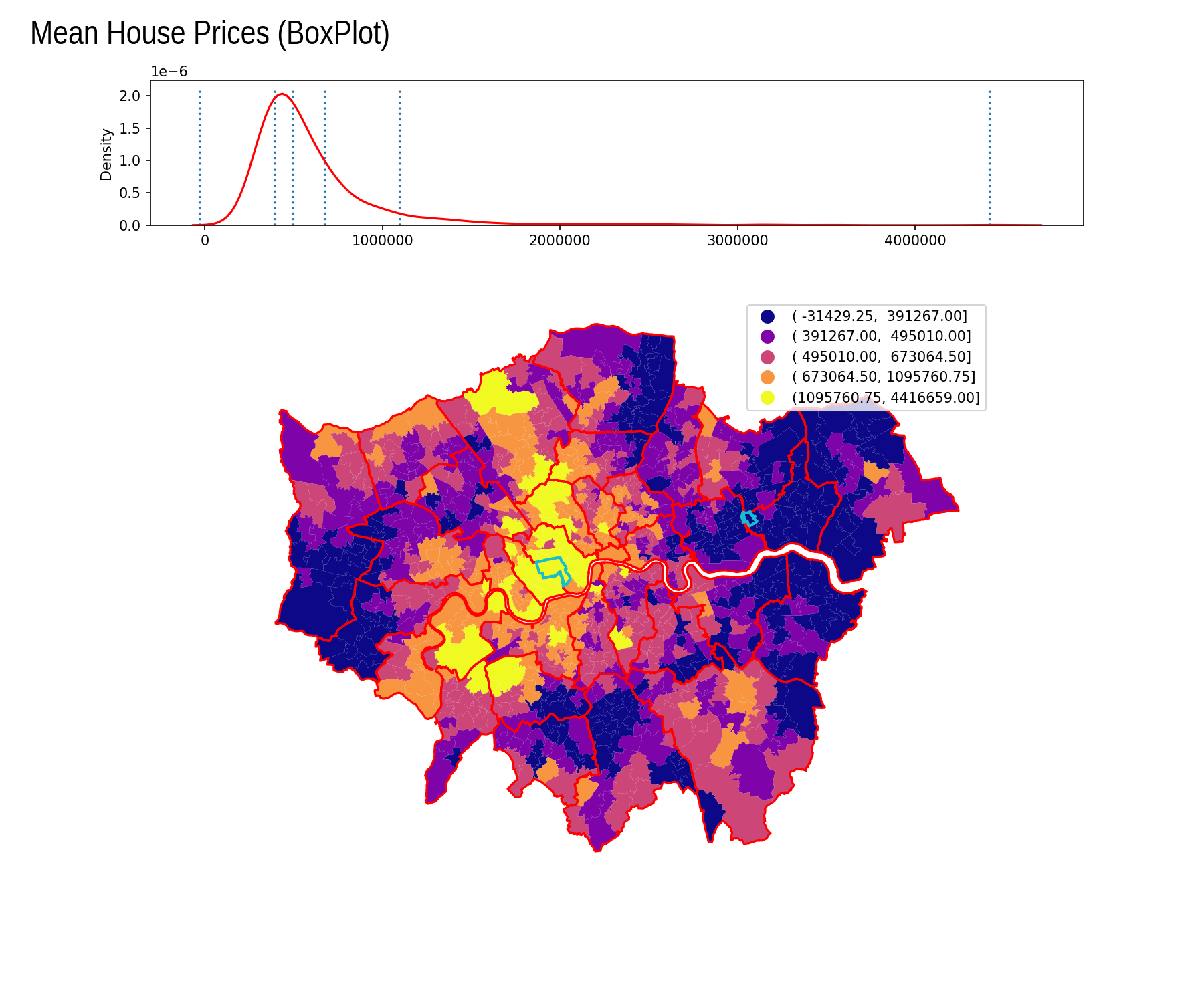
| Interval | Count |
|---|---|
| ( -inf, -31429.25] | 0 |
| ( -31429.25, 391267.00] | 246 |
| ( 391267.00, 495010.00] | 246 |
| ( 495010.00, 673064.50] | 245 |
| ( 673064.50, 1095760.75] | 175 |
| (1095760.75, 4416659.00] | 70 |
Standard Deviations
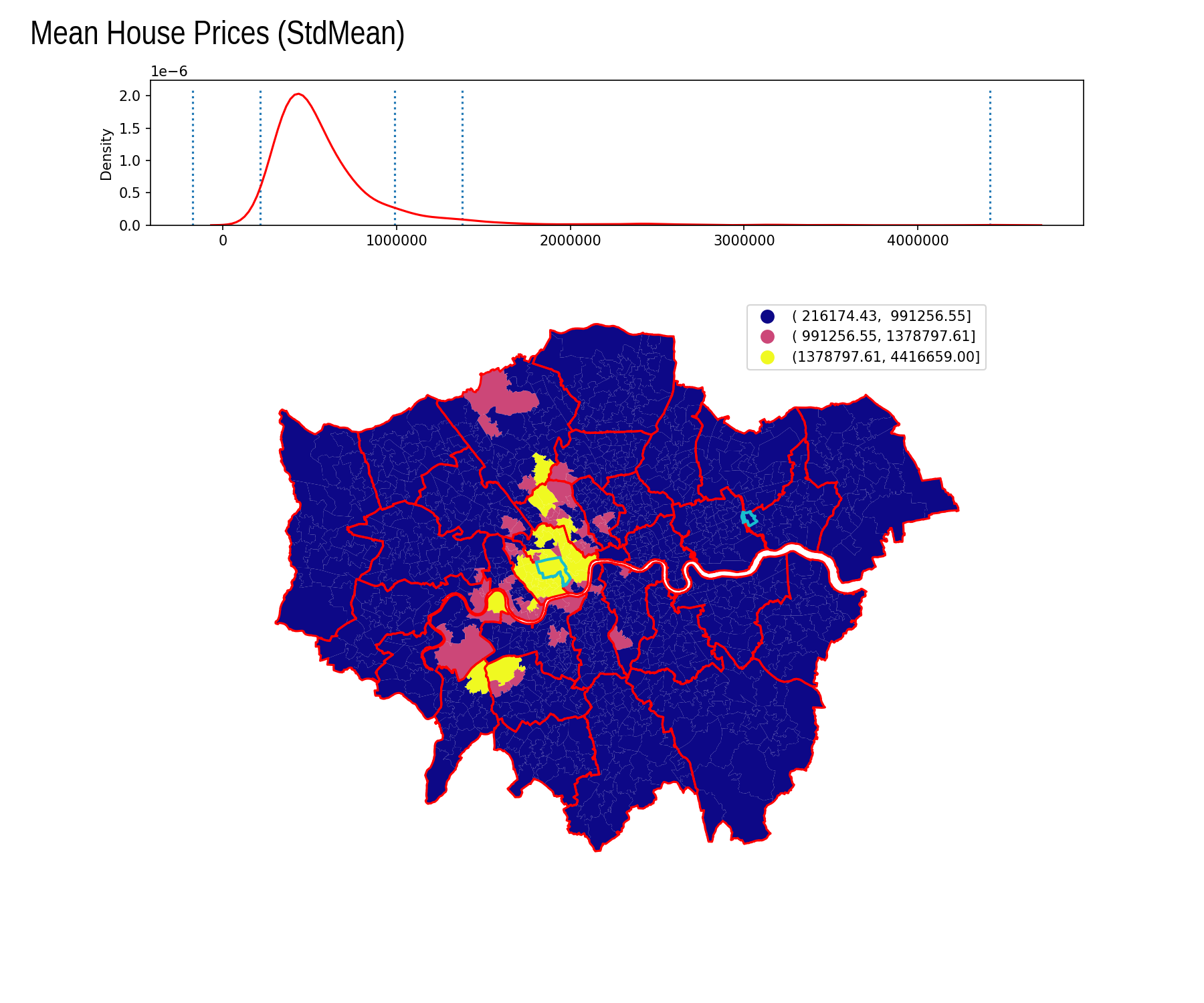
| Interval | Count |
|---|---|
| ( -inf, -171366.63] | 0 |
| (-171366.63, 216174.43] | 0 |
| ( 216174.43, 991256.55] | 892 |
| ( 991256.55, 1378797.61] | 53 |
| (1378797.61, 4416659.00] | 38 |
Max P
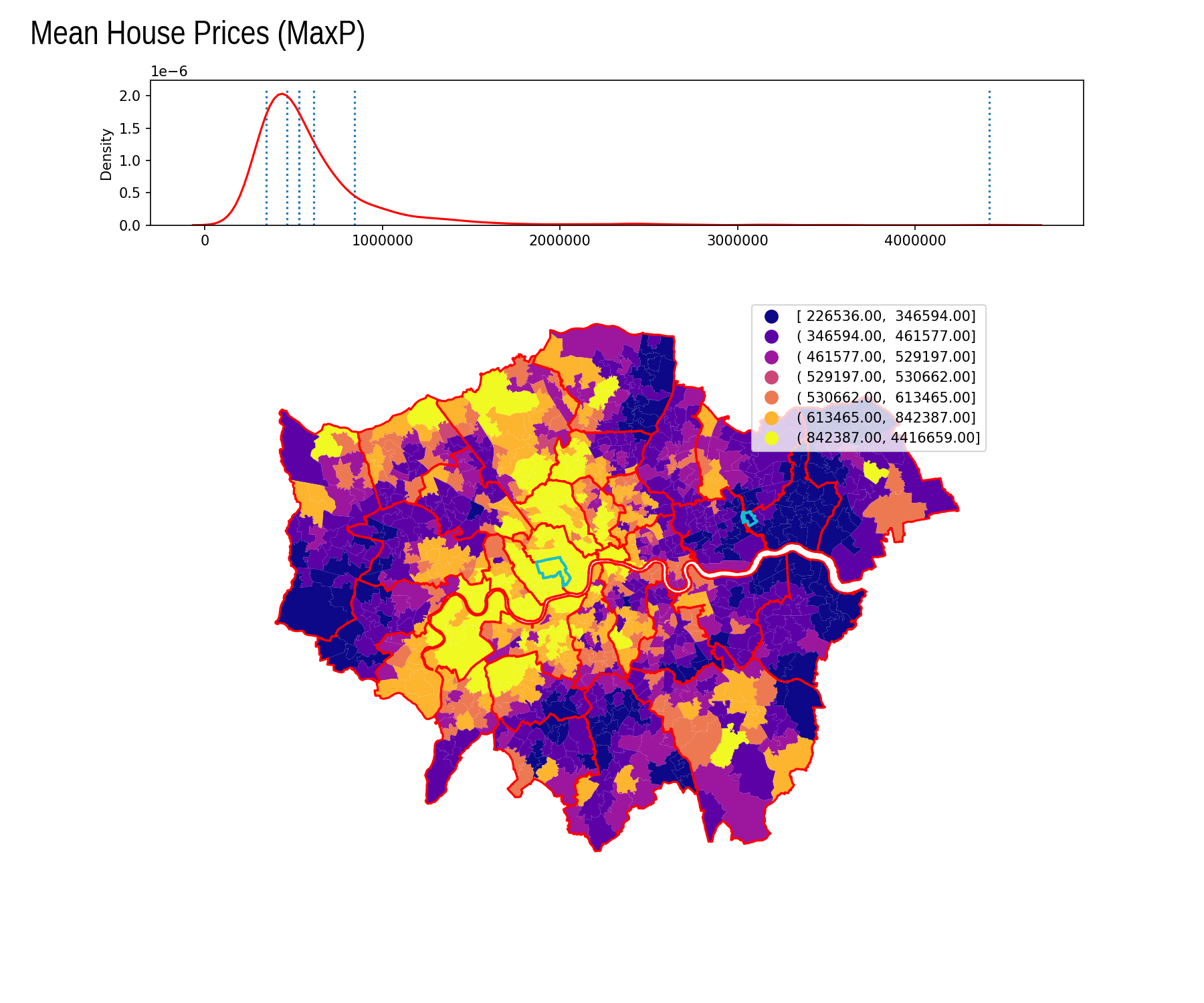
| Interval | Count |
|---|---|
| [ 226536.00, 346594.00] | 142 |
| ( 346594.00, 461577.00] | 279 |
| ( 461577.00, 529197.00] | 140 |
| ( 529197.00, 530662.00] | 3 |
| ( 530662.00, 613465.00] | 115 |
| ( 613465.00, 842387.00] | 167 |
| ( 842387.00, 4416659.00] | 137 |
Head Tail Breaks
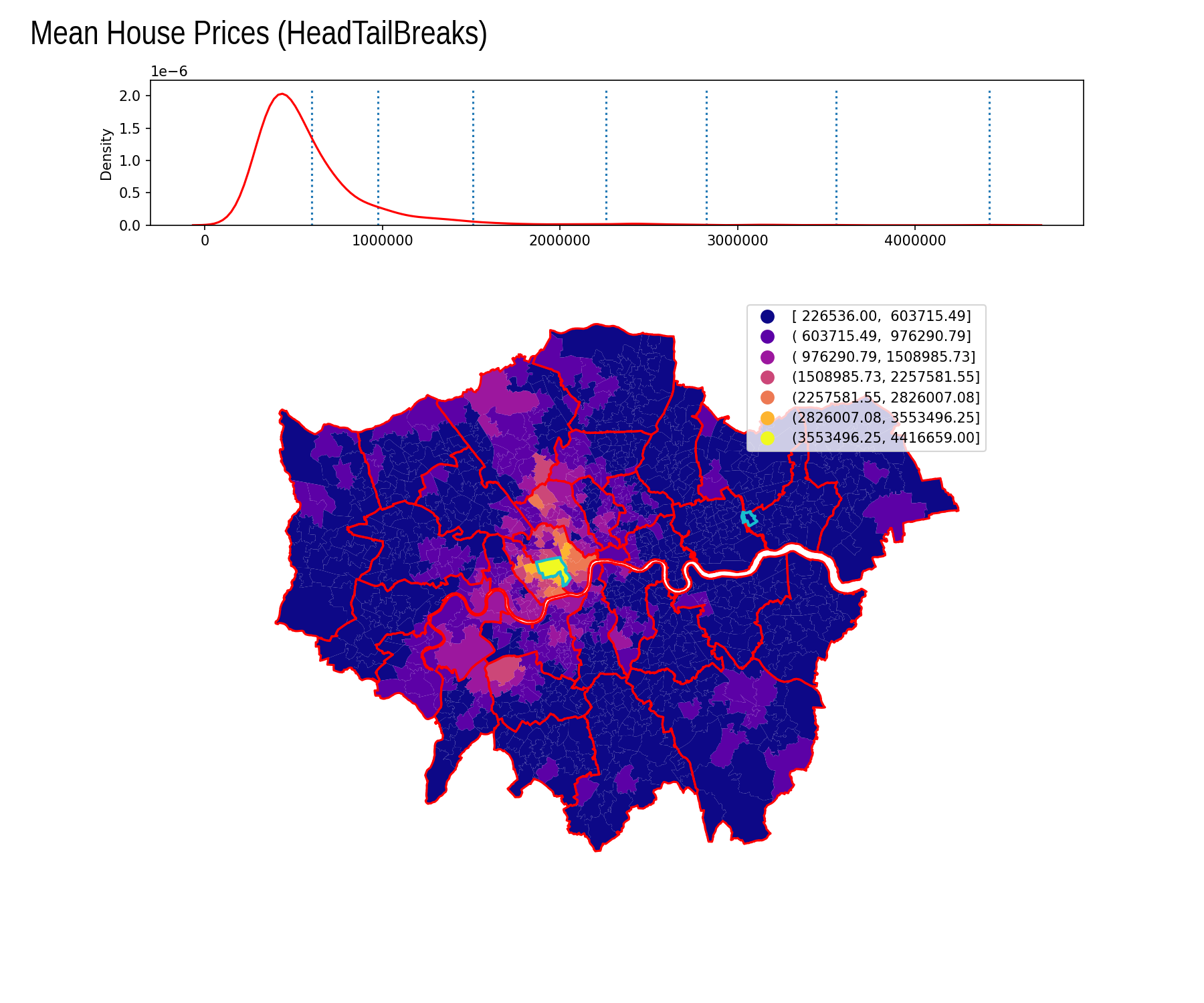
| Interval | Count |
|---|---|
| [ 226536.00, 603715.49] | 670 |
| ( 603715.49, 976290.79] | 218 |
| ( 976290.79, 1508985.73] | 66 |
| (1508985.73, 2257581.55] | 16 |
| (2257581.55, 2826007.08] | 9 |
| (2826007.08, 3553496.25] | 3 |
| (3553496.25, 4416659.00] | 1 |
Equal Interval
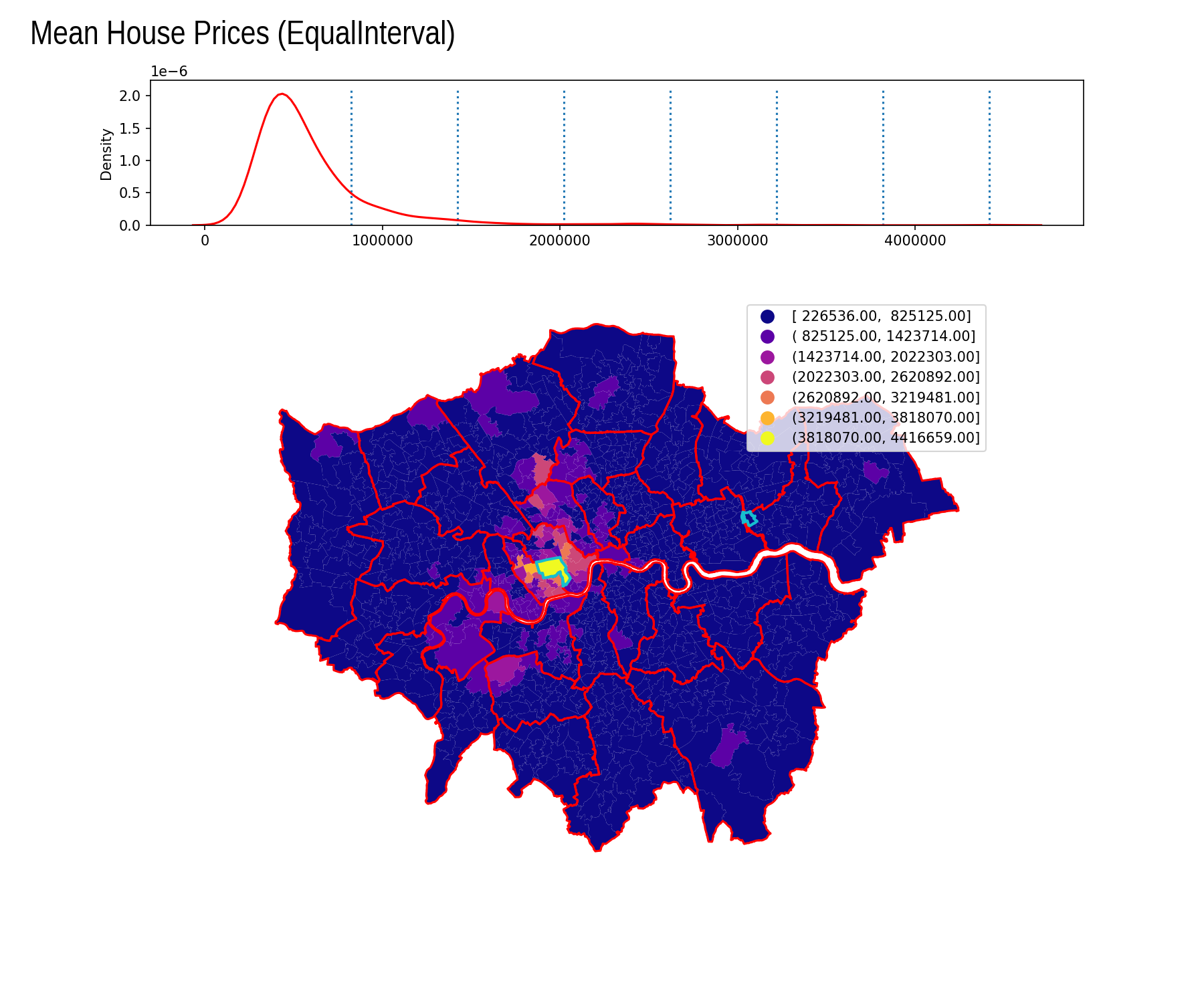
| Interval | Count |
|---|---|
| [ 226536.00, 825125.00] | 842 |
| ( 825125.00, 1423714.00] | 108 |
| (1423714.00, 2022303.00] | 17 |
| (2022303.00, 2620892.00] | 10 |
| (2620892.00, 3219481.00] | 4 |
| (3219481.00, 3818070.00] | 1 |
| (3818070.00, 4416659.00] | 1 |
Quantiles
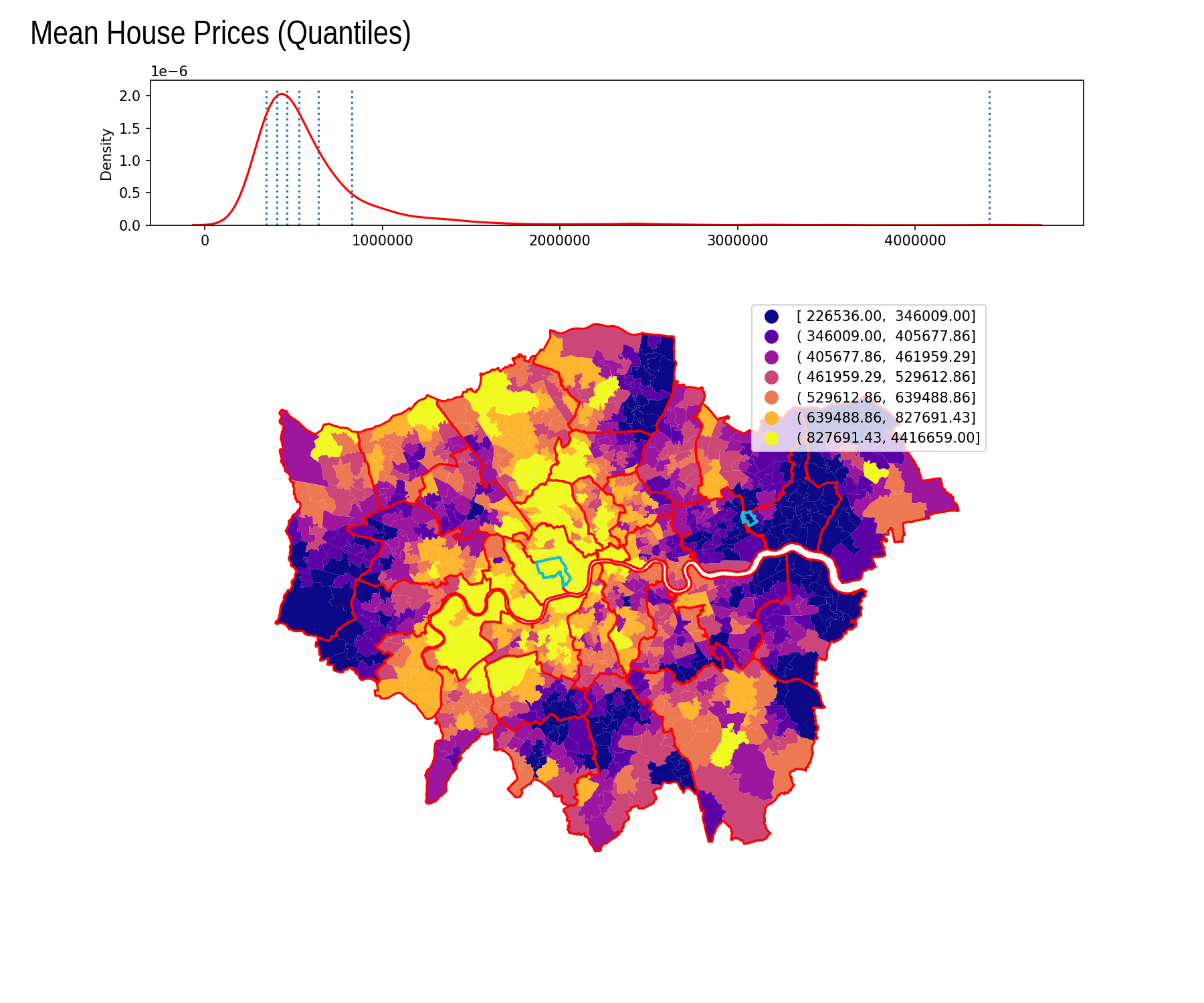
| Interval | Count |
|---|---|
| [ 226536.00, 346009.00] | 140 |
| ( 346009.00, 405677.86] | 140 |
| ( 405677.86, 461959.29] | 140 |
| ( 461959.29, 529612.86] | 141 |
| ( 529612.86, 639488.86] | 140 |
| ( 639488.86, 827691.43] | 140 |
| ( 827691.43, 4416659.00] | 141 |
Natural Breaks
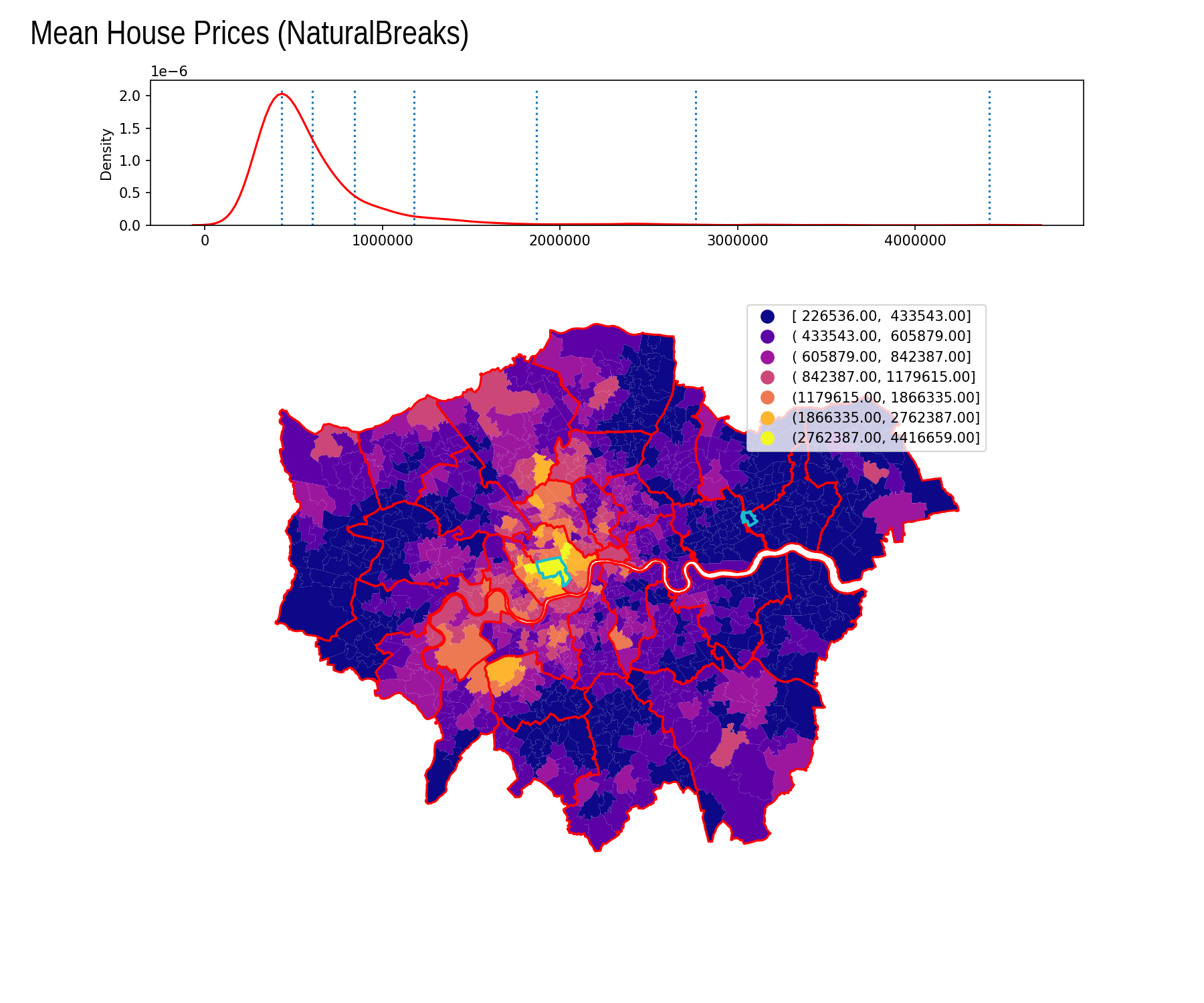
| Interval | Count |
|---|---|
| [ 226536.00, 433543.00] | 356 |
| ( 433543.00, 605879.00] | 316 |
| ( 605879.00, 842387.00] | 174 |
| ( 842387.00, 1179615.00] | 80 |
| (1179615.00, 1866335.00] | 39 |
| (1866335.00, 2762387.00] | 14 |
| (2762387.00, 4416659.00] | 4 |
Maximum Breaks
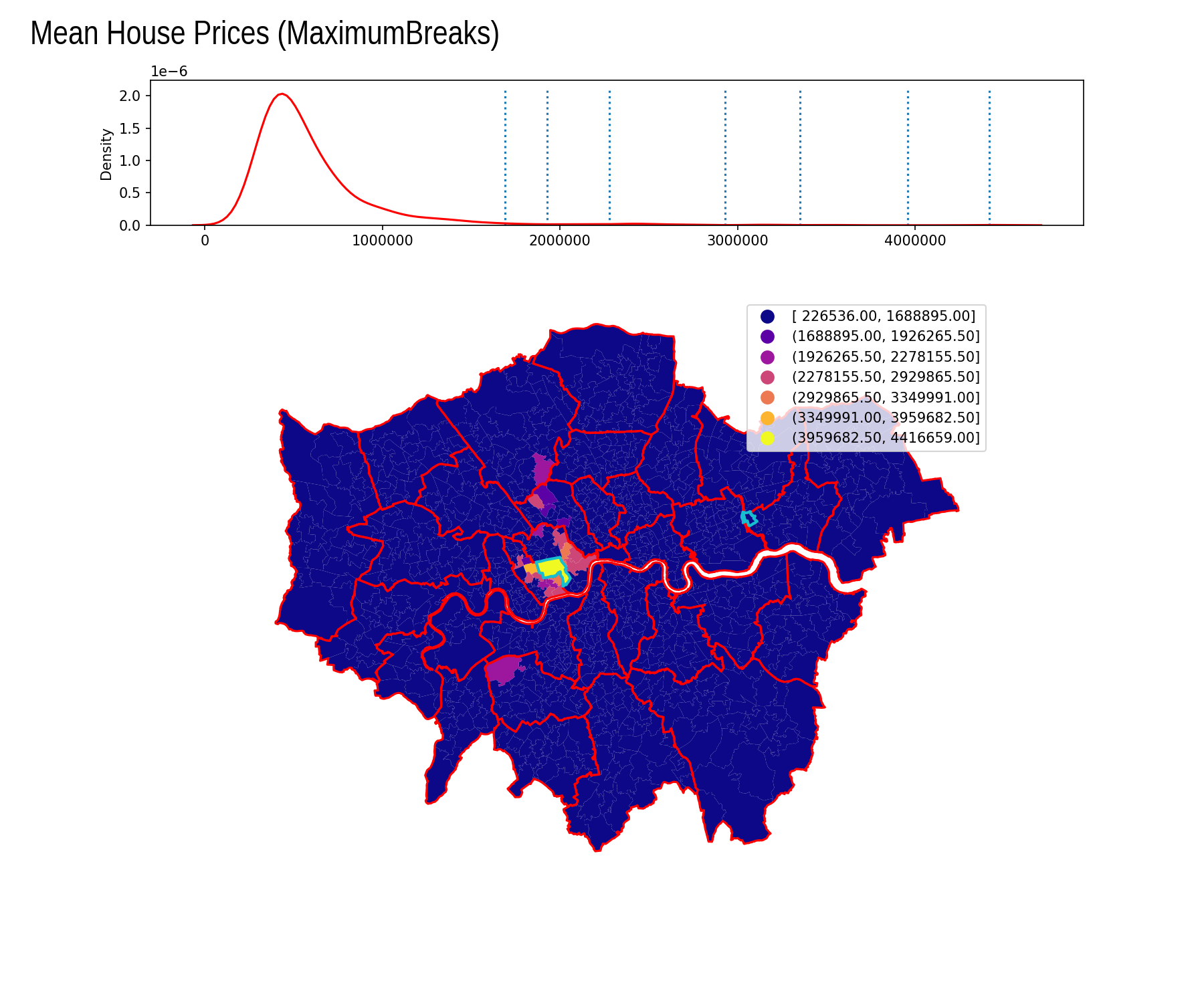
| Interval | Count |
|---|---|
| [ 226536.00, 1688895.00] | 961 |
| (1688895.00, 1926265.50] | 4 |
| (1926265.50, 2278155.50] | 5 |
| (2278155.50, 2929865.50] | 9 |
| (2929865.50, 3349991.00] | 2 |
| (3349991.00, 3959682.50] | 1 |
| (3959682.50, 4416659.00] | 1 |
Fisher Jenks
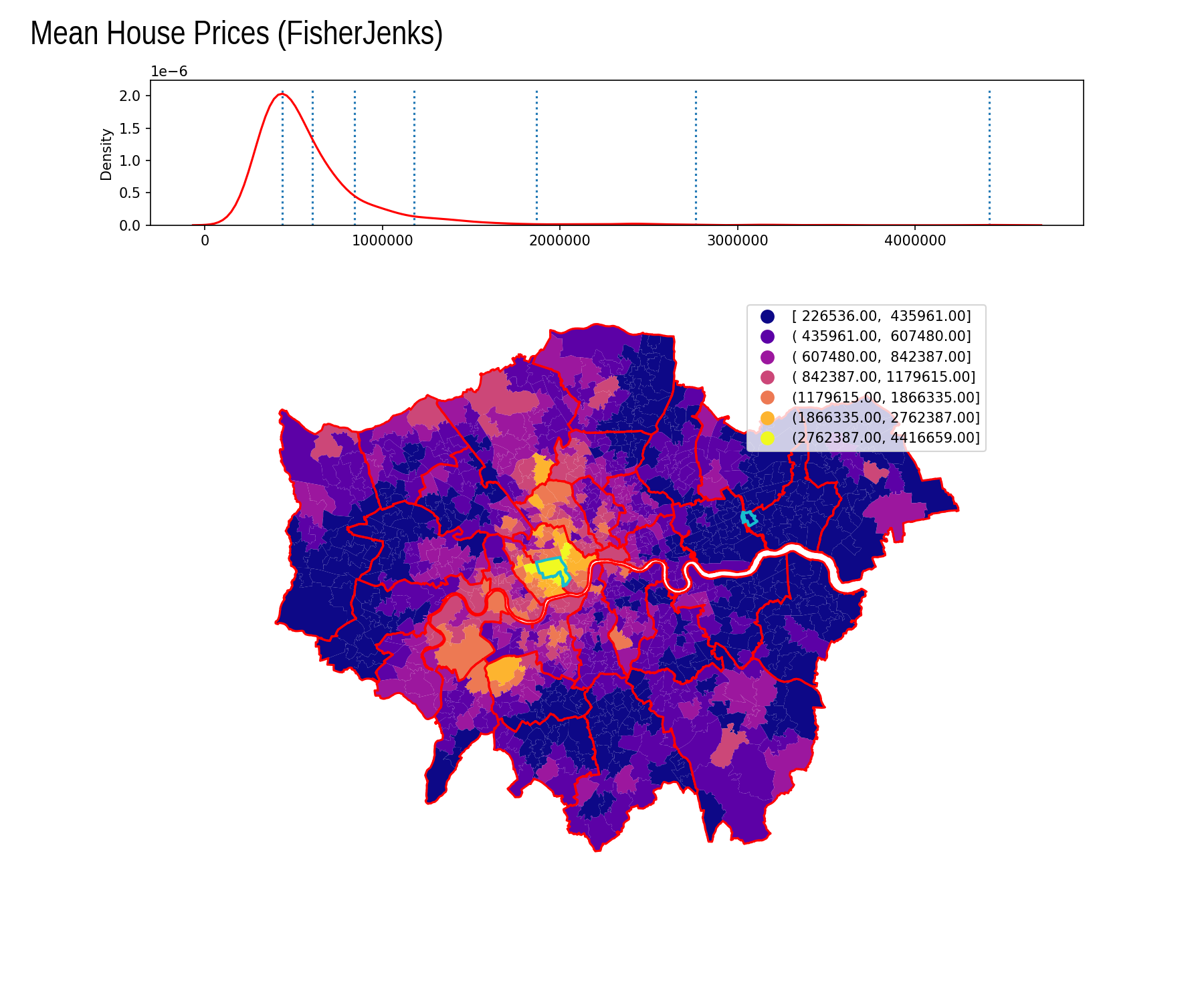
| Interval | Count |
|---|---|
| [ 226536.00, 435961.00] | 363 |
| ( 435961.00, 607480.00] | 310 |
| ( 607480.00, 842387.00] | 173 |
| ( 842387.00, 1179615.00] | 80 |
| (1179615.00, 1866335.00] | 39 |
| (1866335.00, 2762387.00] | 14 |
| (2762387.00, 4416659.00] | 4 |
Jenks Caspall
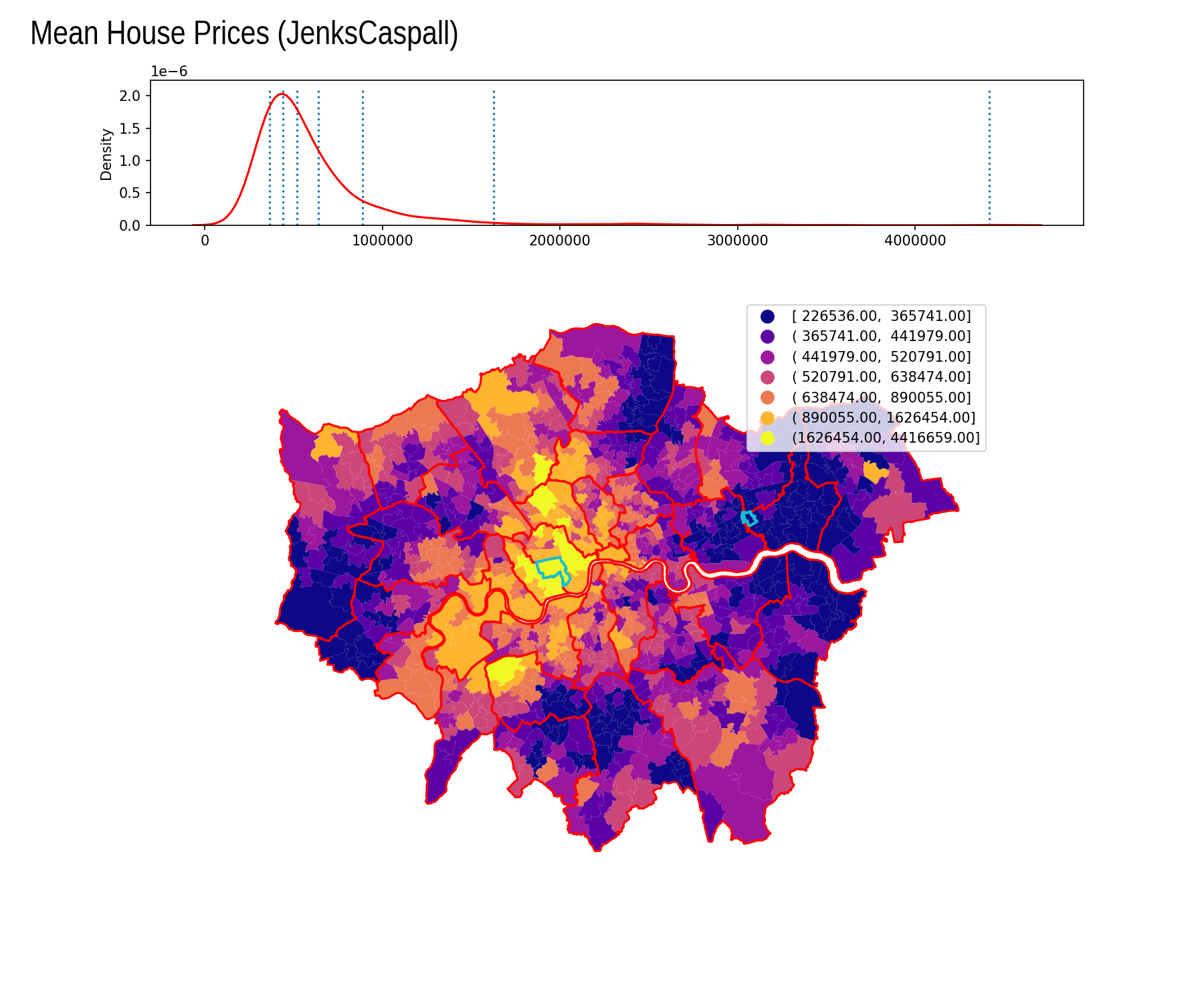
| Interval | Count |
|---|---|
| [ 226536.00, 365741.00] | 188 |
| ( 365741.00, 441979.00] | 187 |
| ( 441979.00, 520791.00] | 167 |
| ( 520791.00, 638474.00] | 160 |
| ( 638474.00, 890055.00] | 156 |
| ( 890055.00, 1626454.00] | 103 |
| (1626454.00, 4416659.00] | 22 |