1
9
6
0
0
1
3
3
8
9Randomness
Jon Reades - j.reades@ucl.ac.uk
1st October 2025
Many things are surprisingly non-random…
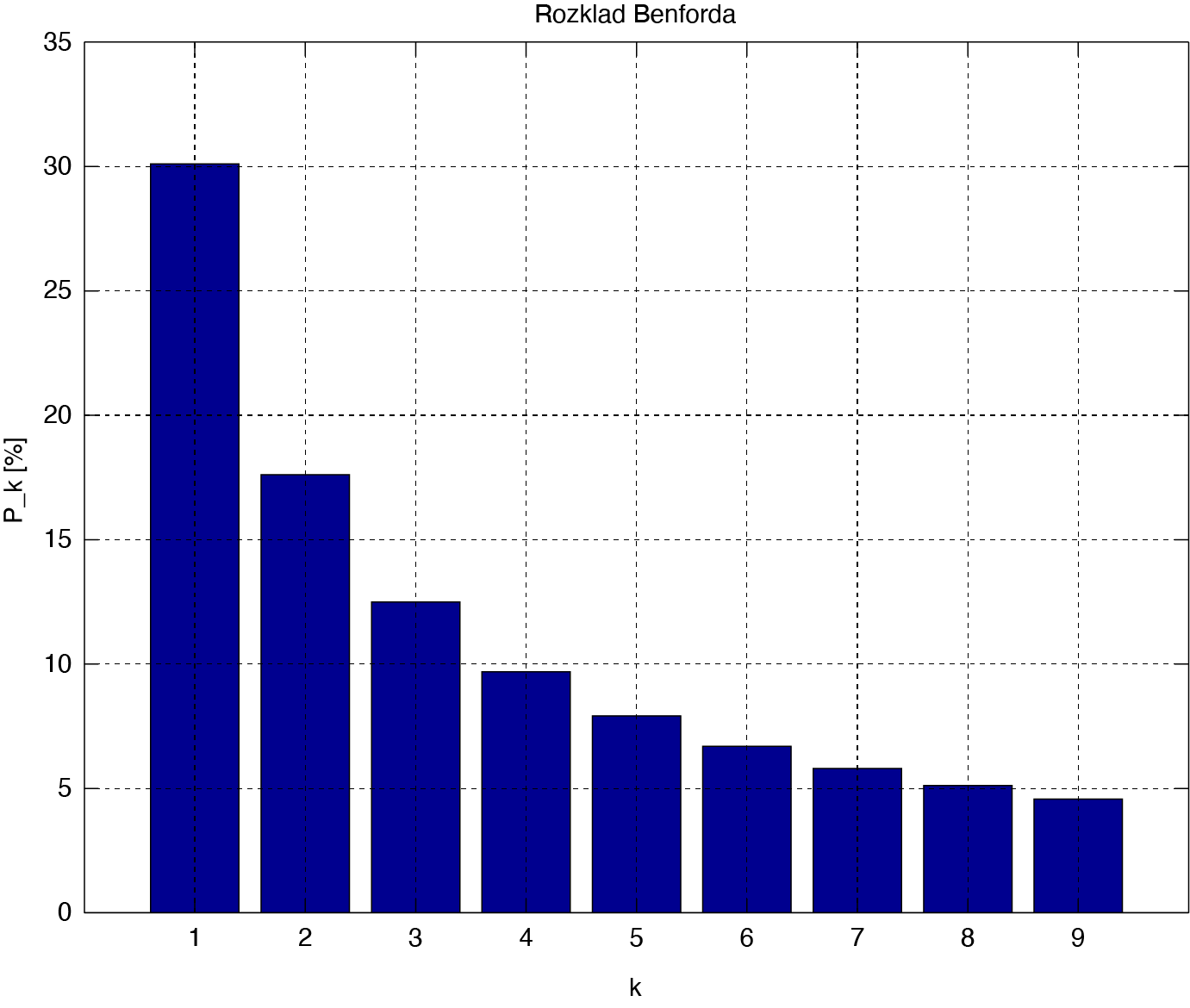
Benford’s Law, which has applications in data science and fraud detection.
Reproducibility: Good or Bad?
Depends on the problem:
- Banking and encryption?
- Sampling and testing?
- Reproducing research/documentation?
Not Very Good Encryption
| Cyphertext | Output |
|---|---|
| ROT0 | To be or not to be, That is the question |
| ROT1 | Up cf ps opu up cf, Uibu jt uif rvftujpo |
| ROT2 | Vq dg qt pqv vq dg, Vjcv ku vjg swguvkqp |
| … | … |
| ROT9 | Cx kn xa wxc cx kn, Cqjc rb cqn zdnbcrxw |
ROT is known as the Caesar Cypher, but since the transformation is simple (A..Z+=x) decryption is easy now. How can we make this harder?
Python is Random
See also: random.randrange, random.choice, random.sample, random.random, random.gauss, etc.
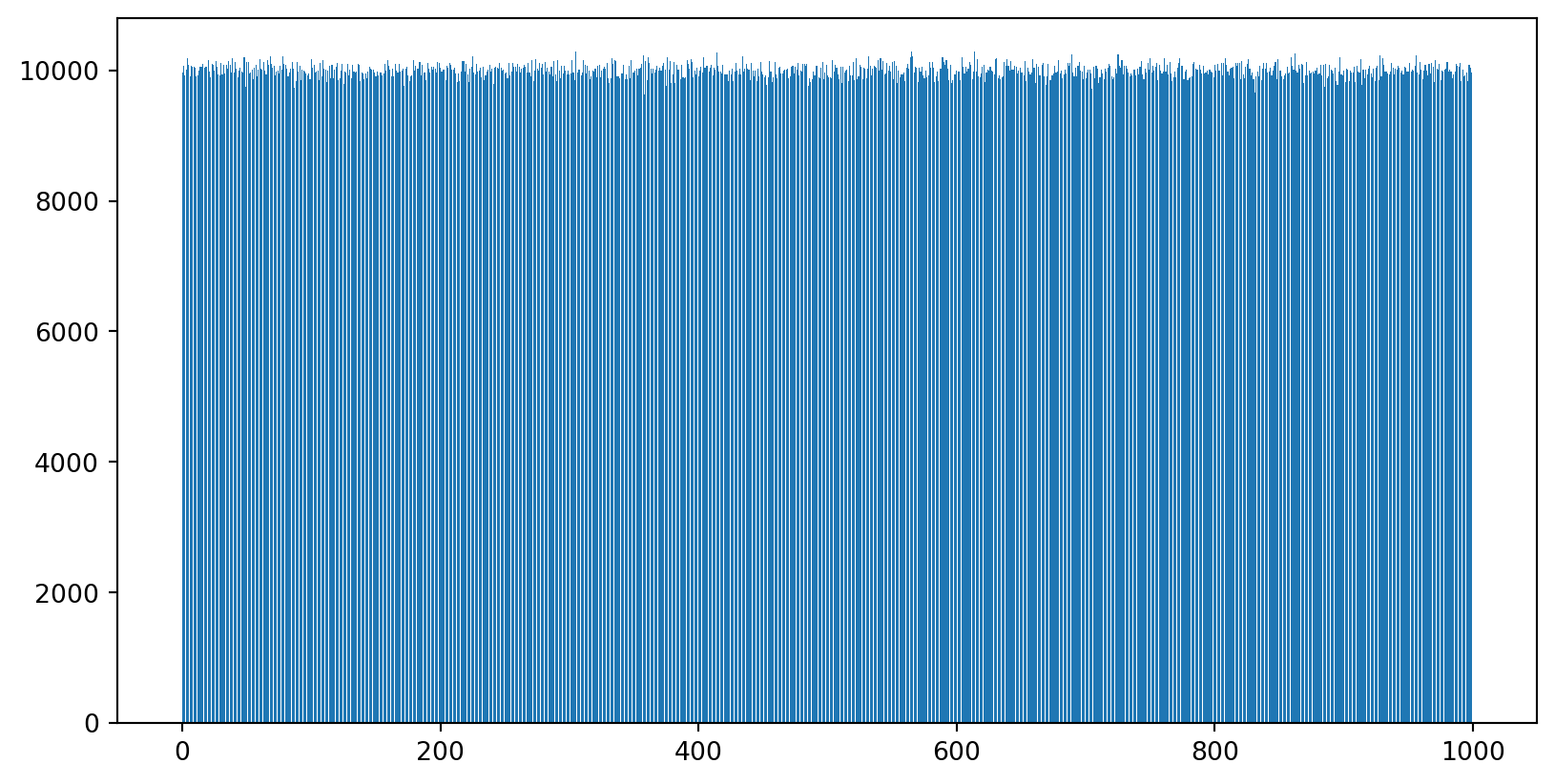
And Repeat…
0 -> 9995
1 -> 10100
2 -> 10099
3 -> 9865
4 -> 9908
5 -> 9874
6 -> 10121
7 -> 10110
8 -> 9859
9 -> 10069Aaaaaaaaaaand Repeat
Answer on next slide…
Aaaaaaaaaaand Repeat
Seeds and Salts
Computers are pseudo-random number generators. Seeds and salts ensure different outputs from the same inputs.1
Just add salt
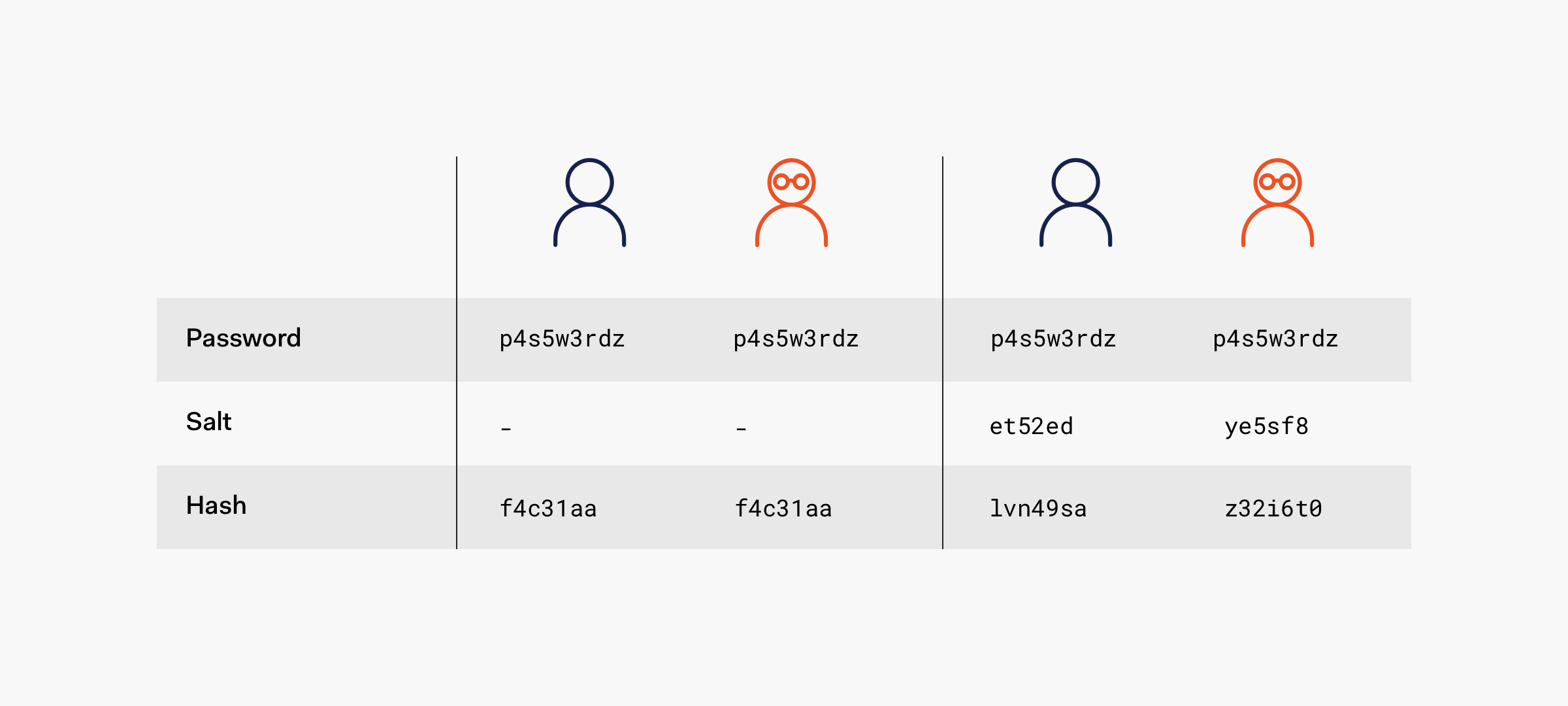
Hashing
Spot the difference:
import hashlib # Can take a 'salt' (similar to a 'seed')
r1 = hashlib.md5('CASA Intro to Programming'.encode())
print(f"The hashed equivalent of r1 is: {r1.hexdigest()}")
r2 = hashlib.md5('CASA Intro to Programming '.encode())
print(f"The hashed equivalent of r2 is: {r2.hexdigest()}")
r3 = hashlib.md5('CASA Intro to Programming'.encode())
print(f"The hashed equivalent of r3 is: {r3.hexdigest()}")The hashed equivalent of r1 is: acd601db5552408851070043947683ef
The hashed equivalent of r2 is: 4458e89e9eb806f1ac60acfdf45d85b6
The hashed equivalent of r3 is: acd601db5552408851070043947683efAnd Note…
The text is 'A Midsummer Night's Dream'
The text is 119,968 characters long
This can be hashed into: 2bd4cfe946d9a97d9ed07631450196afJupyterLab Password
To set a password in JupyterLab you need something like this:
How this was generated:
import uuid, hashlib
salt = uuid.uuid4().hex[:16] # Truncate salt
password = 'casa2021' # Set password
# Here we combine the password and salt to
# 'add complexity' to the hash
hashed_password = hashlib.sha1(password.encode() +
salt.encode()).hexdigest()
print(':'.join(['sha1',salt,hashed_password]))sha1:4b75f2c47bdb41b1:2aa2a7ad58cfc4204fae2d8c029a629df18f1513Encryption & Security
Simple hashing algorithms are not normally secure enough for operational use. Genuine security training takes a whole degree + years of experience.
Areas to look at for more secure computing:
- Public and Private Key Encryption (esp. OpenSSL)
- Privileges used by Applications (esp. Podman vs Docker)
- Revocable Tokens (e.g. for APIs)
- Injection Attacks (esp. for SQL using NULL-byte and similar)
Back to Randomness
Two main libraries where seeds are set:
Seeds and State
Repetition 0:
[10, 1, 0, 4, 3, 3, 2, 1, 10, 8]
Repetition 1:
[10, 1, 0, 4, 3, 3, 2, 1, 10, 8]
Repetition 2:
[10, 1, 0, 4, 3, 3, 2, 1, 10, 8]Question!
Where would you use a mix of randomness and reproducbility as part of a data analysis process?