Data Formats
Jon Reades - j.reades@ucl.ac.uk
1st October 2025
From Files to Data
In order to read a file you need to know a few things:
- What distinguishes one record from another?
- What distinguishes one field from another?
- What ensures that a field or record is valid?
- Does the data set have row or column names? (a.k.a. headers & metadata)
- Is the metadata in a separate file or embedded in the file?
Structure of a Tabular Data File
Row and column names make it a lot easier to find and refer to data (e.g. the ‘East of England row’ or the ‘Total column’) but they are not data and don’t belong in the data set itself.
Usually, one record (a.k.a. observation) finishes and the next one starts with a ‘newline’ (\n) or ’carriage return (\r) or both (\r\n) but it could be anything (e.g. EOR).
Usually, one field (a.k.a. attribute or value) finishes and the next one starts with a comma (,) which gives rise to CSV (Comma-Separate Values), but it could be tabs (\t) or anything else too (; or | or EOF).
Don’t Reinvent the Wheel
Reading data is a very common challenge so… there is a probably a package or class for that! You don’t need to tell Python how to read Excel files, SQL files, web pages… find a package that does it for you!
Most Common Formats
| Extension | Field Separator | Record Separator | Python Package |
|---|---|---|---|
.csv |
, but separator can appear in fields enclosed by ". |
\n but could be \r or \r\n. |
csv |
.tsv or .tab |
\t and unlikely to appear in fields. |
\n but could be \r or \r\n. |
csv (!) |
.xls or .xlsx |
Binary, you need a library to read. | Binary, you need a library to read. | xlrd/xlsxwriter |
.sav or .sas |
Binary, you need a library to read. | Binary, you need a library to read. | pyreadstat |
.json, .geojson |
Complex (,, [], {}), but plain text. |
Complex (,, [], {}), but plain text |
json, geojson |
.feather |
Binary, you need a library to read. | Binary, you need a library to read. | pyarrow, geofeather |
.parquet |
Binary, you need a library to read. | Binary, you need a library to read. | pyarrow |
‘Mapping’ Data Types
You will often see the term ‘mapping’ used in connection to data that is not spatial, what do they mean? A map is the term used in some programming languages for a dict! So it’s about key : value pairs again.
Here’s a mapping
| Input (e.g. Excel) | Output (e.g. Python) |
|---|---|
| NULL, N/A, “” | None or np.nan |
| 0..n | int |
| 0.00…n | float |
| True/False, Y/N, 1/0 | bool |
| R, G, B (etc.) | int or str (technically a set, but hard to use with data sets) |
| ‘Jon Reades’, ‘Huanfa Chen’, etc. | str |
| ‘3-FEB-2020’, ‘10/25/20’, etc. | datetime module (date, datetime or time) |
Testing a Mapping
Working out an appropriate mapping (representation of the data) is hugely time-consuming.
It’s commonly held that 80% of data science is data cleaning.
The Unix utilities (grep, awk, tail, head) can be very useful for quickly exploring the data in order to develop a basic understanding of the data and to catch obvious errors.
You should never assume that the data matches the spec.
Why This Isn’t Easy
Label These 1
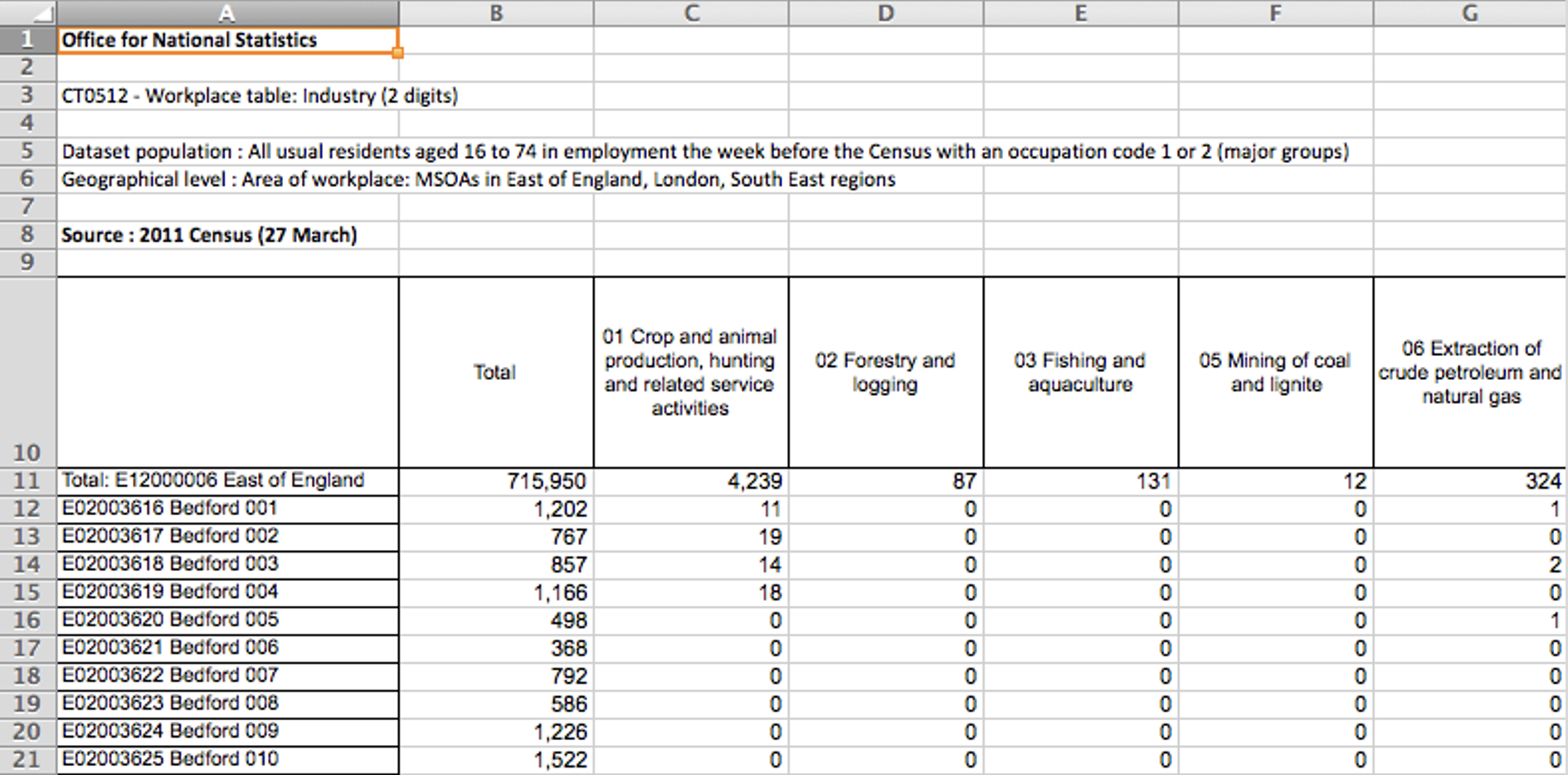
Label These 2

And Here’s Data for Jaipur, India
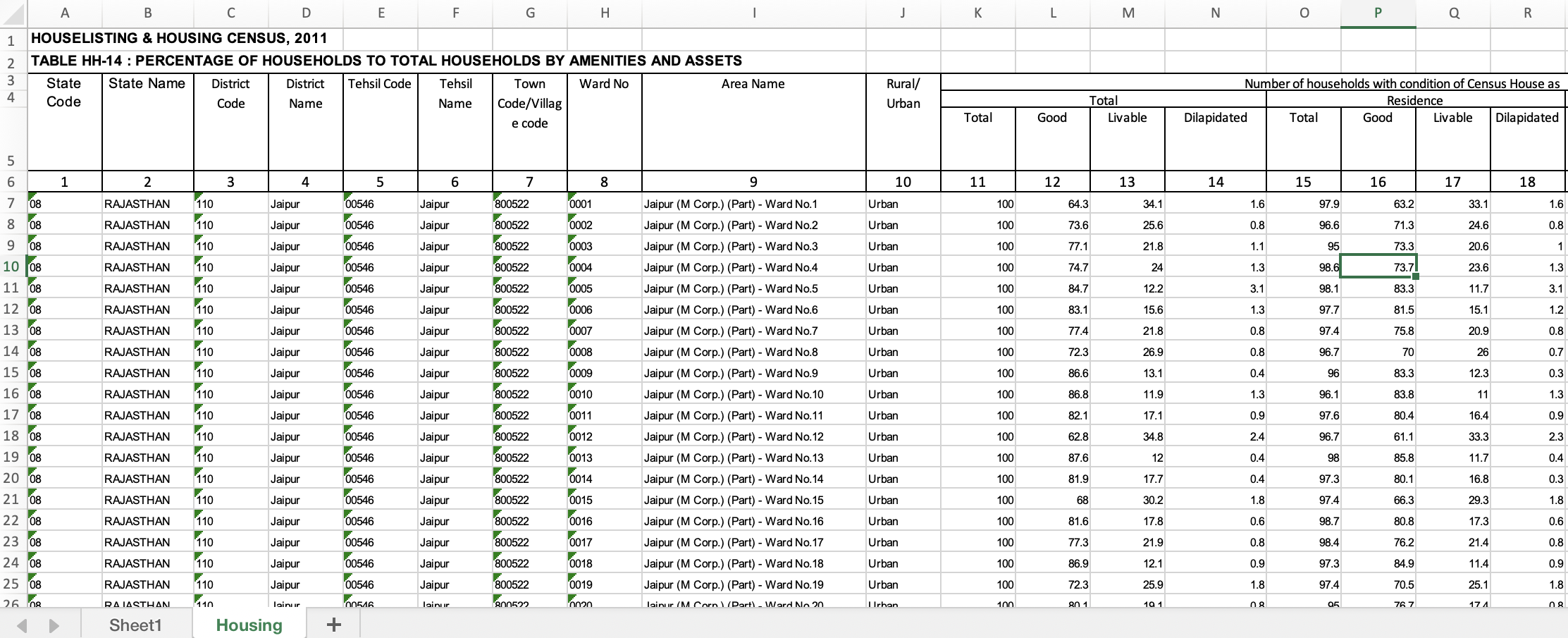 1
1
Things That Can Go Wrong…
A selection of real issues I’ve seen in my life:
- Truncation: server ran out of diskspace or memory, or a file transfer was interrupted.
- Translation: headers don’t line up with data.
- Swapping: column order differs from spec.
- Incompleteness: range of real values differs from spec.
- Corruption: field delimitters included in field values.
- Errors: data entry errors resulted in incorrect values or the spec is downright wrong.
- Irrelevance: fields that simply aren’t relevant to your analysis.
These will generally require you to engage with columns and rows (via sampling) on an individual level.