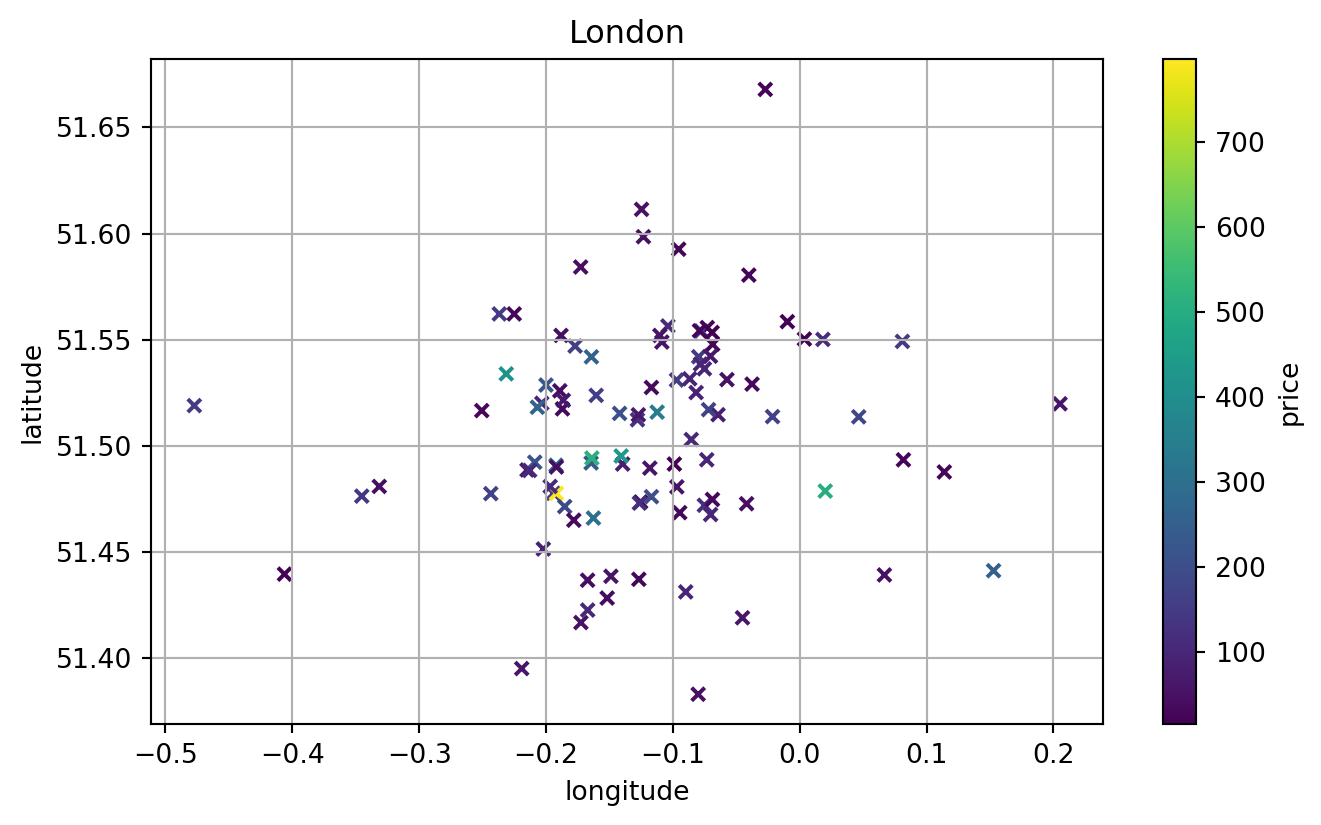
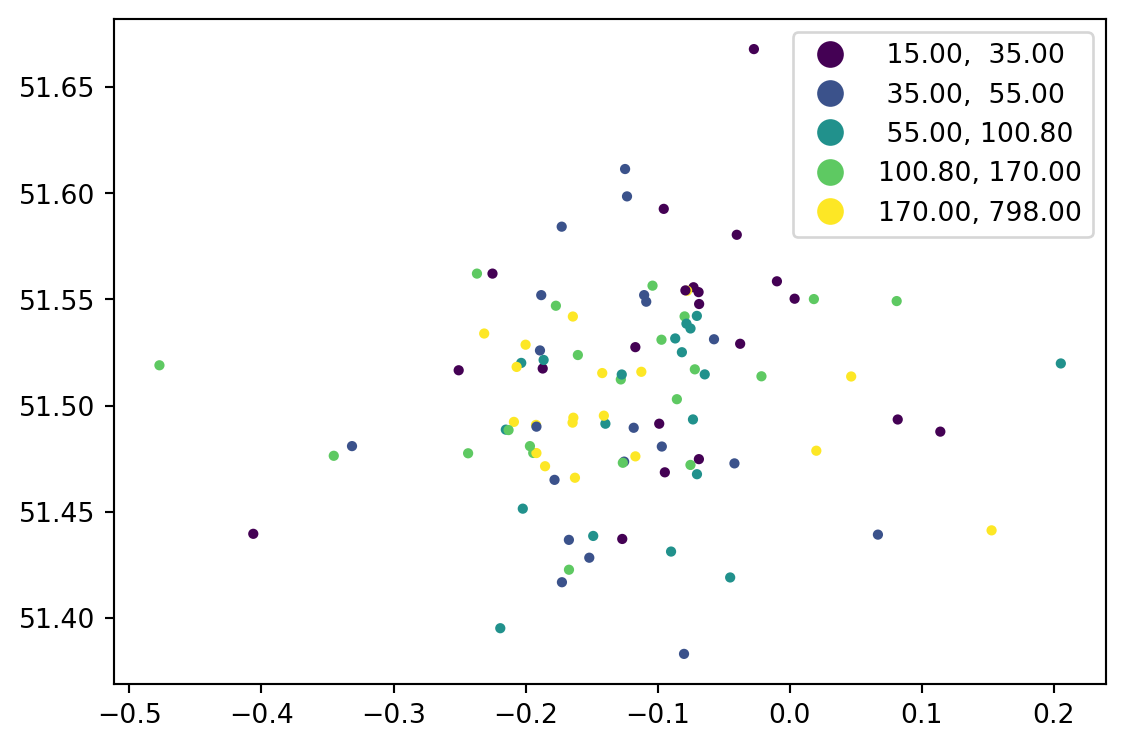
import pandas as pd
import geopandas as gpd
url='https://bit.ly/3I0XDrq'
df = pd.read_csv(url)
df.set_index('id', inplace=True)
df['price'] = df.price.str.replace('$','',regex=False).astype('float')
gdf = gpd.GeoDataFrame(df,
geometry=gpd.points_from_xy(
df['longitude'],
df['latitude'],
crs='epsg:4326'
)
)Exploratory
Data Analysis
- j.reades@ucl.ac.uk
1st October 2025
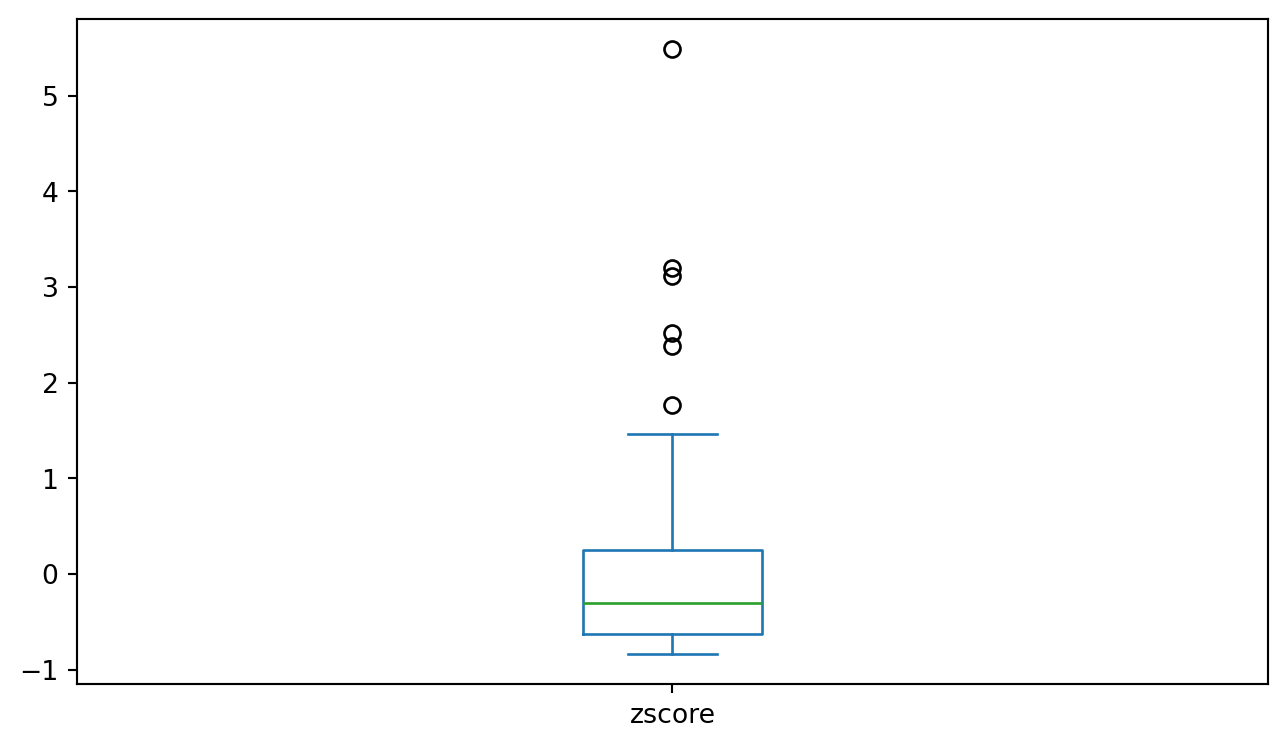
More Complex Measures
Pandas also makes it easy to derive new variables… Here’s the z-score:
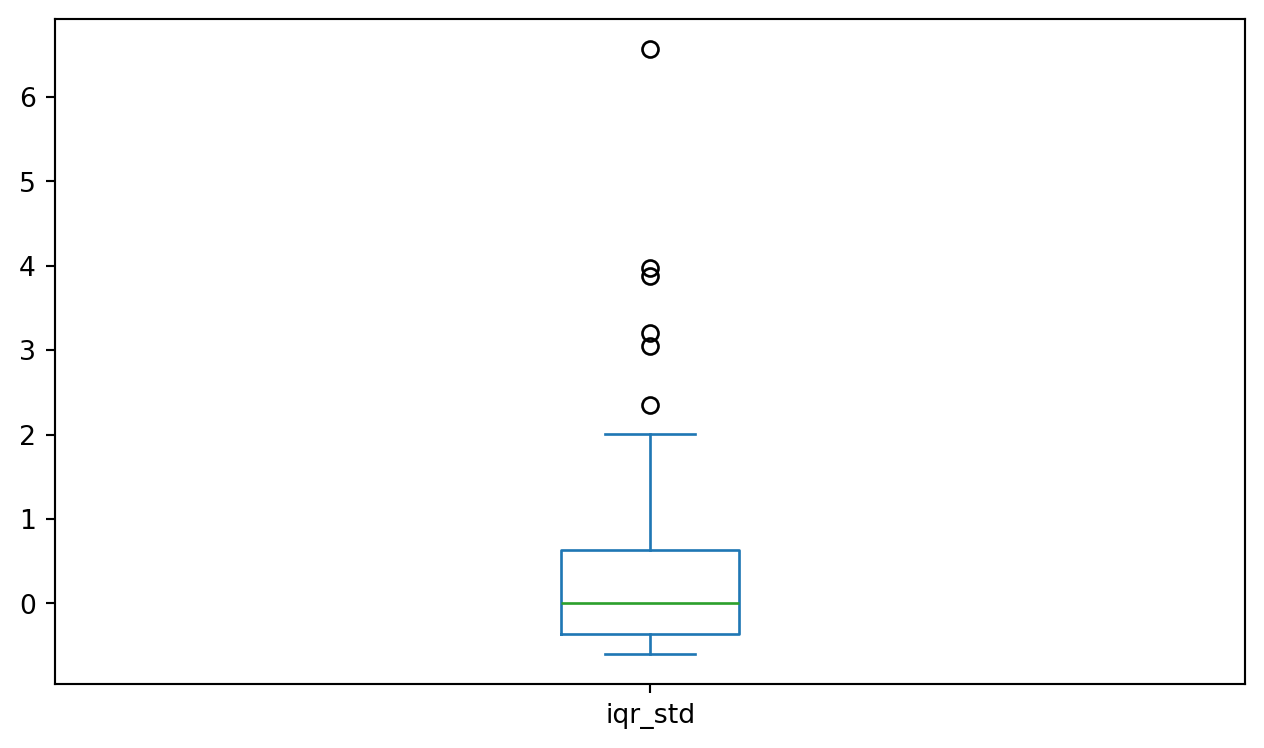
And Even More Complex
And here’s the Interquartile Range Standardised score:
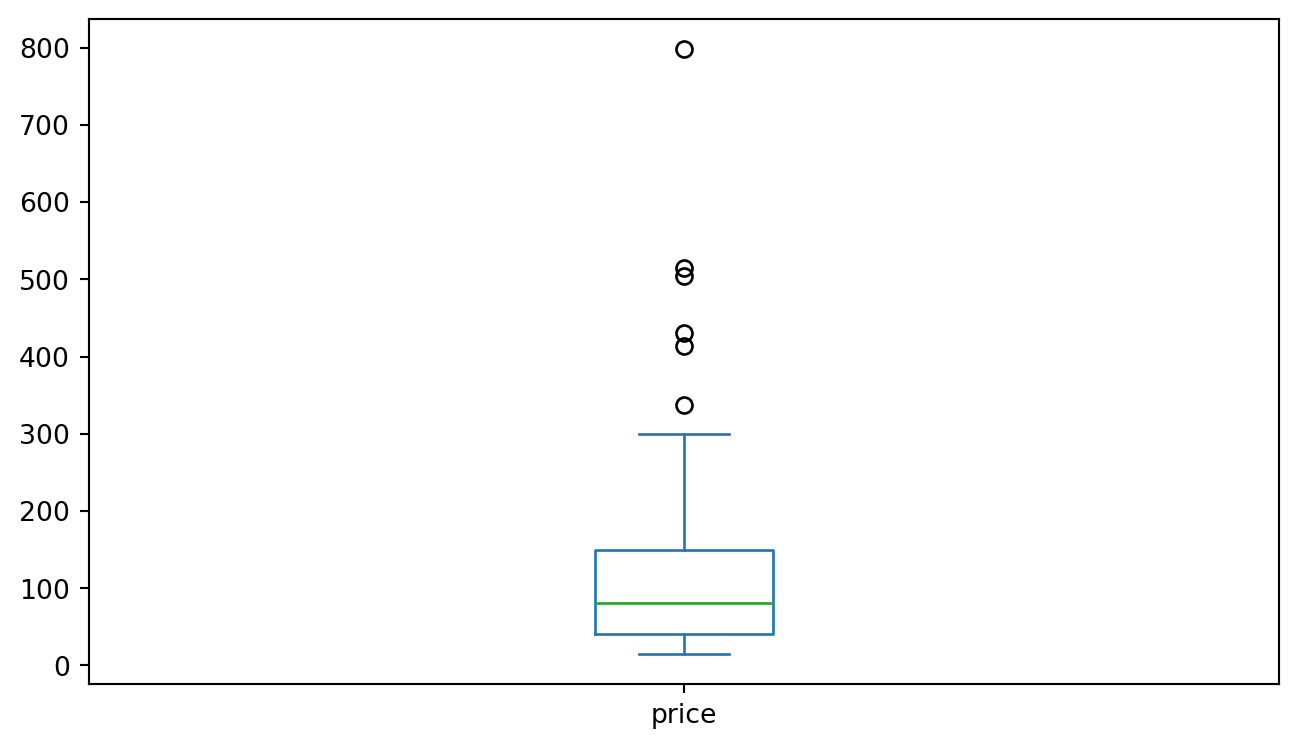
Boxplot
Frequency
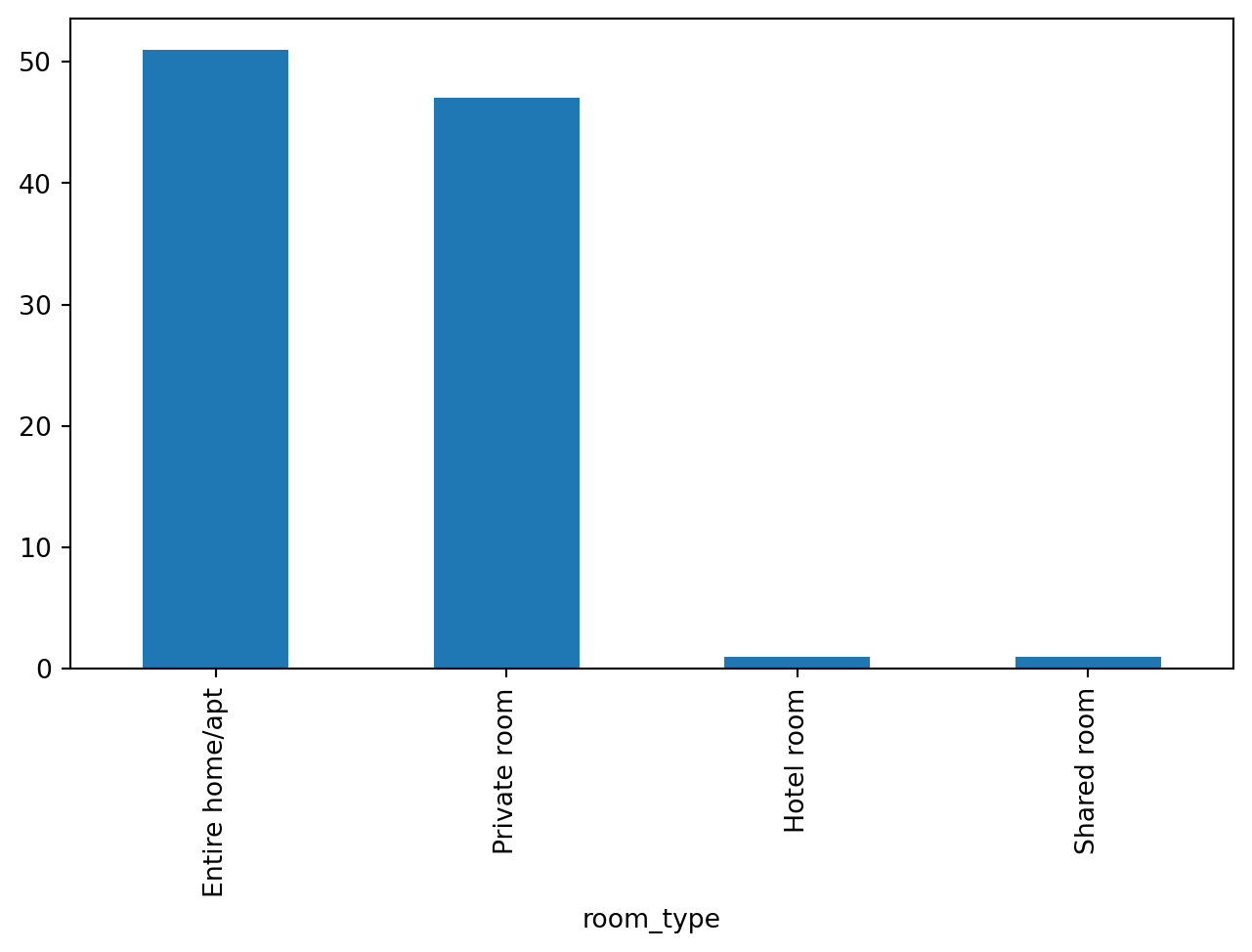
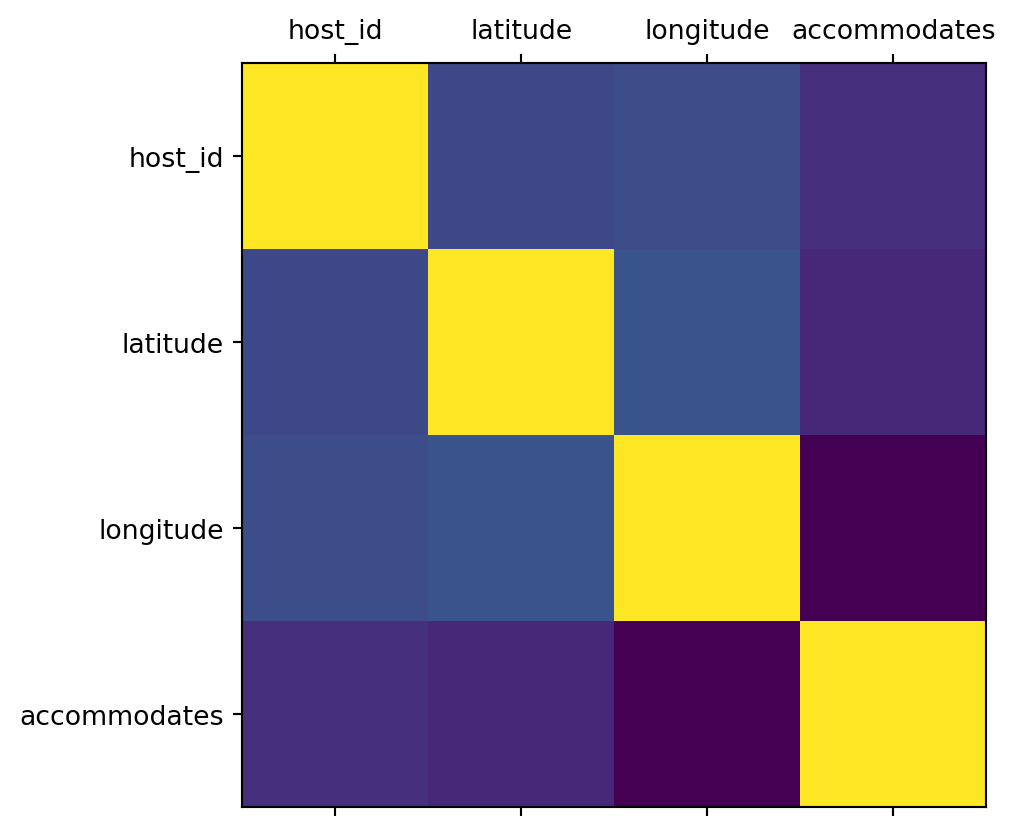
A Correlation Heatmap
We’ll get to these in more detail in a couple of weeks, but here’s some output…