Jon Reades - j.reades@ucl.ac.uk
1st October 2025
count()
first()
last()
mean()
median()
min()
max()
std()
var()
mad()
prod()
sum()
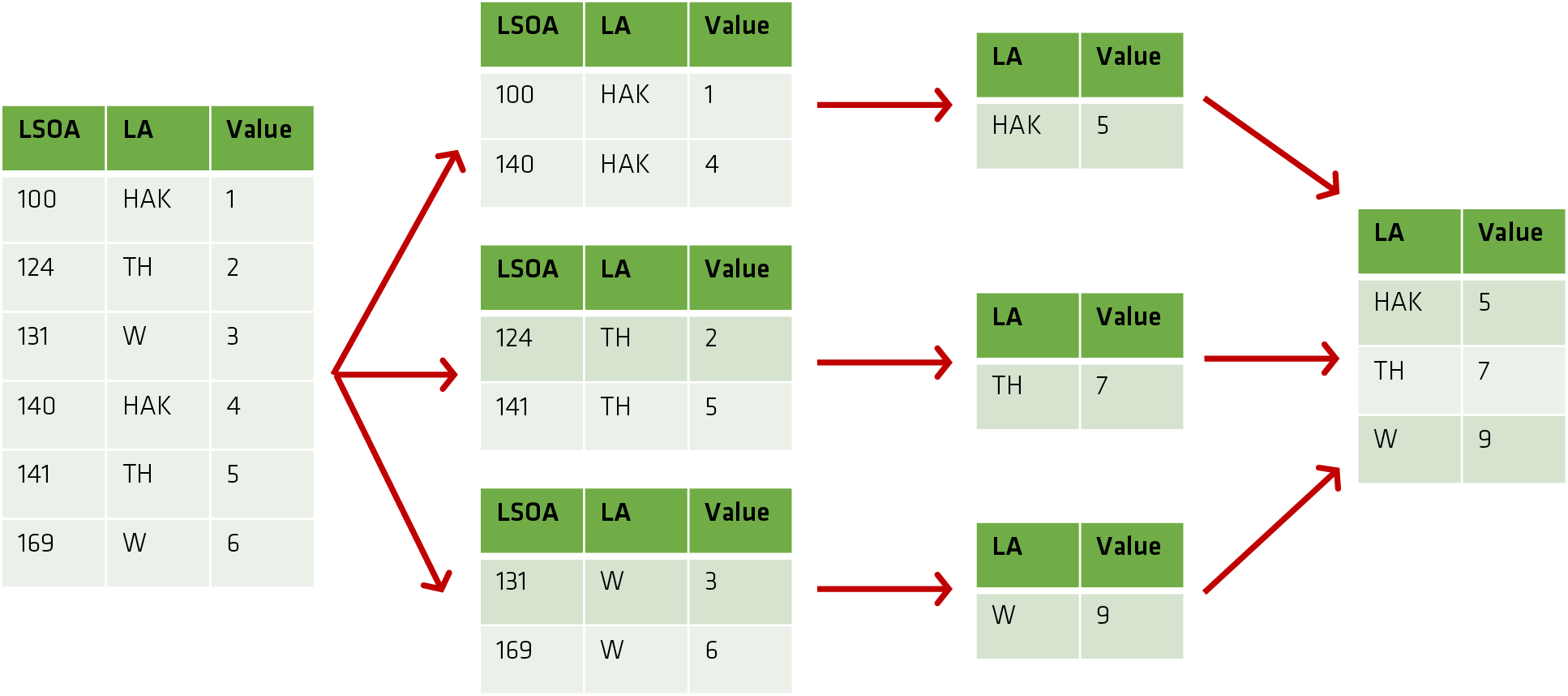
In Pandas these follow a split / apply / combine approach:
grouped_df = df.groupby(<fields>).<function>
For instance, if we had a Local Authority (LA) field:
LA
grouped_df = df.groupby('LA').sum()
Using apply the function could be anything:
apply
def norm_by_data(x): # x is a column from the grouped df x['d1'] /= x['d2'].sum() return x df.groupby('LA').apply(norm_by_data)
mapping = {'HAK':'Inner', 'TH':'Outer', 'W':'Inner'} df.set_index('LA', inplace=True) df.groupby(mapping).sum()
A ‘special case’ of Group By features:
pandas.cut(<series>, <bins>)
age = pd.cut(titanic['age'], [0, 18, 80]) titanic.pivot_table('survived', ['sex', age], 'class')